What is a Suffix Tree?
Lets discuss Suffix Trees in Details with its construction and usage
Basically, the Suffix Tree is a Trie-like data structure that represents all the suffixes of text.

The definition of suffix trees can be given as: A suffix tree for a n-character string T[1 …n] is a rooted tree with the following properties:
- A suffix tree will contain n leaves which are numbered from 1 to n
- Each internal node (except root) should have at least 2 children
- Each edge in a tree is labeled by a nonempty substring of T
- No two edges of a node (children edges) begin with the same character
- The paths from the root to the leaves represent all the suffixes of T
The Construction of Suffix Trees -
Algorithm:
- Let S be the set of all suffixes of T. Append $ to each of the suffixes.
- Sort the suffixes in S based on their first character.
- For each group S:
- If a group has only one element, then create a leaf node.
- Otherwise, find the longest common prefix of the suffixes in S-group, create an internal node, and recursively continue with Step 2, S being the set of remaining suffixes from S after splitting off the longest common prefix.
Example — Let the given text be T = tatat.
For this string, we give a number to each of the suffixes.

Now, sort the suffixes based on their initial characters.

Group S1 has index-1 ; Group S2 has index-3 and 5 ; Group S3 has index-2,4 and 6.
In the three groups, the first group has only one element. So, as per the algorithm, create a leaf node for it.

Now, for S2 and S3 (as they have more than one element), find the longest prefix in the group.

For S2 and S3, create internal nodes, and the edge contains the longest common prefix of those groups.

Now we have to remove the longest common prefix from the S2 and S3 group elements.

Out next step is solving S2 and S3 recursively. First let us take S2. In this group, if we sort them based on their first character, it is easy to see that the first group contains only one element $, and the second group also contains only one element, at $. Since both groups have only one element, we can directly create leaf nodes for them.
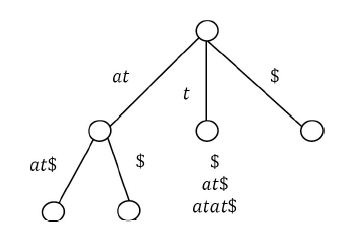
At this step, both S1 and S2 elements are done and the only remaining group is S3. As similar to earlier steps, in the S3 group, if we sort them based on their first character, it is easy to see that there is only one element in the first group and it is $. For S3 remaining elements, remove the longest common prefix.

In the S3 second group, there are two elements: $ and at$. We can directly add the leaf nodes for the first group element $. Let us add S3 subtree.
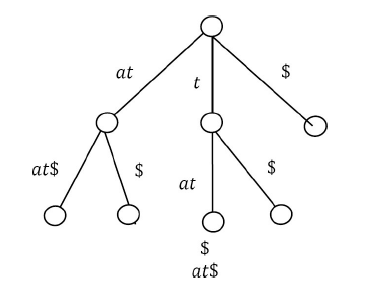
Now, S3 contains two elements. If we sort them based on their first character, it is easy to see that there are only two elements and among them one is $ and other is at$. We can directly add the leaf nodes for them. Let us add S3 subtree.
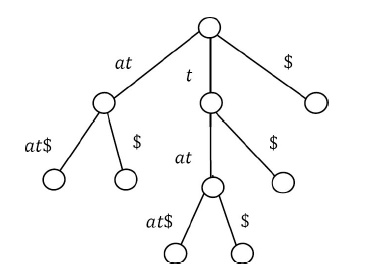
Since there are no more elements, this is the completion of the construction of the suffix tree for string T = tatat.
Time Complexity : O(n^2)
Note:
- There are O(n) algorithms for constructing suffix trees.
- To improve the complexity, we can use indices instead of string for branches.
Some applications of Suffix Trees :
- Exact String Matching.
- Longest Repeated Substring.
- Longest Palindrome.
- Longest Common Substring.
- Longest Common Prefix.
- Search for a regular expression.
- Find the first occurrence of a pattern in the text.
